The dict type is not only widely used in our programs but also a fundamental part of the python implementation. Module namesapce, class and instance attributes and funciton keyword arguments are some of the fundamental constructs where dictionaries are deployed.
Hash tables are the engines behind python’s dicts and sets.
hashable
An object is hashable if it has a hash value which never changes during its lifetime, and can be compared to other objects. Hashable objects which compare eqaul must have the same hash value.
The atomic immutable types (str, bytes, numeric types) are all hashable. All of python’s immutable built-in objects are hashable except tuple, because tupe may contain reference to unhashable objects.
1 | # the various means of building a dict: |
dict comprehensions
Since python 2.7 the syntax of listcomps and genexps was applied to dict comprehensions and set comprehensions. A dictcomp builds a dict instance buy producing key:value pair from any iterable.
1 | # dict comprehensions example |
Handling missing Keys
d.get(key, default) is an alternative to d[key] whenever a default value is more convenient than handling KeyError.
When updating the value found in dict, using either getitem or get is awkward and inefficient. d.setdefault(key, default) is another option to update dict, which provides a significant speedup by avoiding redundant key lookups.
1 | info = {'xiao': [1,3,4], 'ming': [3,4,5,6]} |
Mapping with flexible key lookup
Sometimes it is convenient to have mappings that return some made-up value when a missing key is searched. There are two main approaches to this: one is to use a default dict instead of plain dict. The other is to subclass dict or any other mapping type and add a missing method.
defaultdict
collections.defaultdict provides a solution to elegantly handle the missing keys. When instantiating a defaultdict, you provide a callable which is used to produce a default value whenever getitem is passed a non-existent key argument.
1 | # example of defaultdict |
The missing method
Underlying the way mappings deal with missing keys is the aptly named missing method. This method is not defined in the base dict class, but dict is aware of it if you subclass dict and provide a missing method, the standard dict.getitem will call it whenever a key is not found, instead of raising KeyError
1 | class StrKeyDict(dict): |
Variations of dict
The various mapping types included in collections module of the standard library.
collections.OrderedDict
Maintains keys in insertion order, allowing iteration over items in a predictable order. The popitem method of an OrderedDict pops the first item by default, but if called as my_odict.popitem(last=True), it pops the last item added.
collections.ChainMap
Holds a list of mappings which can be searched as one. The lookup is performed on each mapping in order, and succeeds if the key is found in any them.
collections.Counter
A mapping that holds an integer count for each key. Updating an existing key adds to its count. This can be used to count instances of hashable objects (the keys ) or as a multiset – a set that hold serveral occurrences of each element.
1 | import collections |
collections.UserDict
A pure python implementation of a mapping that works like a standard dict, which is designed to be subclassed. The main reason why it’s preferable ot subclass from UserDict than dict is that the built-in has some implementation shortcust that end up forcing us to override methods that we can just inherit from UserDict with no problems.
1 | from collections import UserDict |
Immutable mappings
Since python 3.3 the types module provides a wrapper class MappingProxyType, which given a mapping, returns a mappingproxy instance that is a read-only but dynamic view of the original mapping.
1 | from types import MappingProxyType |
Set theory
A set is a collection of unique objects, a basic use case is removing duplication.
Set elements must be hashable.
Set types implement the essential set operations as infix operators.1
2
3
4
5
6
7
8
9
10
11
12# given two sets sl and sh
sl = set([1,2,3,4,3,2])
sh = set([3,4,5,6,4])
sl # output => set([1, 2, 3, 4])
sh # output => set([3,4,5,6])
# sl | sh returns their union
sl | sh # output => set([1, 2, 3, 4, 5, 6])
# sl & sh returns their intersection
sl & sh # output => set([3,4])
# sl - sh returns the difference
sl - sh # output => set([1, 2])
sh - sl # output => set([5,6])
set literals
The syntax of set literals – {1}, {1, 2}, looks exactly like the math notation. But, there is no literal notation for the empty set, we must use set() to initiate a empty set. If you write {}, you are creating an empty dict.
Literal set syntax like {1, 2, 3} is both faster and more readable than calling the constructor set([1,2,3]).
frozenset has no special syntax to represent, they must be created by calling the constructor.1
2
3frozenset(range(10))
# output => frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
`
set comprehensions
Set comprehensions (setcomps) were added in python 2.7.1
2{chr(i) for i in range(32, 40)}
# output => set(['!', ' ', '#', '"', '%', '$', "'", '&'])
The hash table algorithm
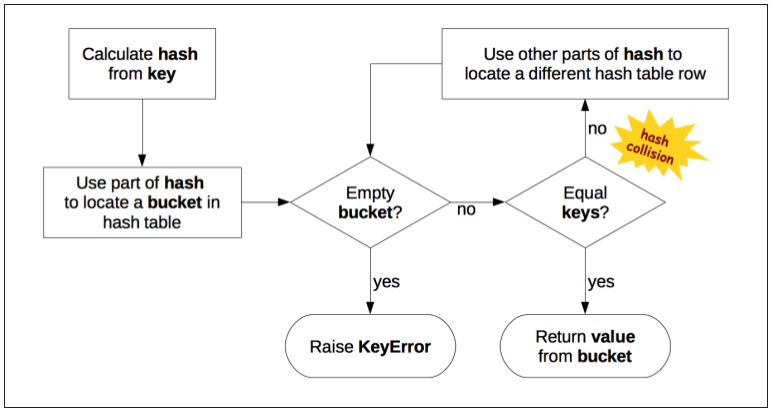
To fetch the value of my_dict[search_key], python calls hash(search_key) to obtain the hash value of search_key and uses the least significant bits of that number as offset to look up a bucket in hash table (the number of bits used depends on the current size of the table). If the found bucket is empty, KeyError is raised. Otherwise the found bucket has an item – a found_key:found_value pair, and then python checks whether search_key == fund_key. if they match, that was the item sought: found_value is returned.
However, if search_key and found_key do not match, this is a hash collision. This happens because a hash function maps arbitrary objects to a small number of bits, and in addition the hash table is indexed with a subset of those bits. To resolve the collision, the algorithm then takes different bits in the hash, massages them in a particular way and uses the result as an offset to look up a different bucket. If that is empty, KeyError is raised; If not, either the keys match and the item value is returned, or the collision resolution process is repeated.
Futher reading dict implementation Principles
The Process to insert or update an item is the same, except that when an empty bucket is located, the new item is put there, and when a bucket with a matching key if found, the value in that bucket is overwritten with the new value.
Additionally, when inserting items python may determine that the hash table is too crowded and rebuild it to a new location with more room. As the hash table grows, so does the number of hash bits used as bucket offsets, and this keeps the rate of collision low.
Pratical consequences of how dict works
keys must be hashable objects
- It supports the hash() function via a hash() method that always returns the same value over the lifetime of the object.
- It supperts equality via an eq() method
- If a == b is True then hash(a) == hash(b) must also be True
User-defined types are hashable by default because their hash value is their id() and they all compare not equal.
dicts have significant memory overhead
Because a dict uses a hash table internally, and hash tables must be sparse to work, they are not space efficient. For example, if you are handling a large quantity of records it makes sense to store thme in a list of tuples or named tuples instead of using a list of dictionaries in JSON style, with one dict per record. Replacing dicts with tuples reduces them memory usage in two ways: by removing the overhead of one hash table per record and by not storing the field names again with each record.
Key search is very fast
The dict implementation is an example of trading space for time: dictionaries have significant memory overhead, but they provide fast access regardless of the size of the dictionary, as long as it fits in memory.
Key ordering depends on insertion order
When a hash collision happens, the second key ends up in position that it would not normally occupy if it had been inserted first. So ad dict builts as dict([(key1, value1), (key2, value2)]) compares equal to dict([(key2, value2), (key1, value1)]), but their key ordering may not be the same if the hashes of key1 and key2 collide.
Adding items to a dict may change the order of existing keys
Whenever you add a new item to a dict, the python interpretor may decide that the hash table of that dictionary needs to grow. This entails building a new, bigger hash table, and adding all current items to the new table. During this process, new(but different) hash coillsions may happen, with the result taht the keys are likely to be ordered differently in the new hash table. All of this is implementation-dependent, so you cannot reliably predict when it happen.
If you are iterating over the dictionary keys and changing them at the same time, your loop may not scan all the items as expected.
Practical consequences of how sets work
The set and frozenset types are also implemented with a hash table, except that each bucket holds only a reference to the element(as if it were a key in a dict, but without a value to go with it).
- Set elements must be hashable objects
- Sets have a significant memory overhead
- Membership testing is very efficent
- Element ordering depends on insertion order
- Adding elements to a set may change the order of other elements
Other mappings
- defaultdict
- OrderedDict
- ChainMap
- Counter