Character issues
The concept of “string” is simple enough: a string is a sequence of characters. In python 3 str are Unicode character, just like the items of a unicode object in python 2, while in python 2 str are the raw bytes.
The Unicode standard explicitly separates the identity of characters from specific byte representations.
- The identify of a character – its code point – is a number from 0 to 1,114,111 (base 10), shown in the Unicode standard as 4 to 6 hexadecimal digits with a ‘U+’ prefix. For example, the code point for letter A is U+0041
- The actual bytes that represent a charactor depend on the encoding in use. An encoding is an algorithm that converts code points to byte sequences and vice-versa. The code point for A(U+0041) is encoded as the single byte \x41 in the UTF-9 encoding, or as the bytes \x41\x00 in UTF-16LE encoding.
1 | # in python 2 |
1 | # in python 3 |
Byte essentials
There are two basic built-in types for binary sequences: the immutable bytes type introduced in python 3 and the mutable bytearray, added in python 2.6.
Each item in bytes or bytearray is an integer from 0 to 255, and not a 1-character string like in the python 2 str.
Althogh binary sequences area really sequences of integers, their literal notation reflects the fact that ASCII text is often embedded in them. Therefore, three different displays are used:
- For bytes in the printable ASCII range – from space to ~, the ASCII character itself is used.
- For bytes corresponding to tab, newline, carriage return and \, the escape sequences \t \n \r and \ are used.
- For every other byte value, an hexadecimal escape sequence is used, e.g. \x00 is the null type.
1 | s = 'fei我的 hehe' |
Structs and memory views
The struct module provides functions to parse packed bytes into a tuple of fields of different types and to perform the opposite conversion, from a tuple into packed bytes.1
2
3
4
5
6
7import struct
# struct format: < little-endian: 3s3s two sequences of 3 bytes; HH two 16-bit integers
fmt = '<3s3sHH'
s = 'abcd我的'
s # output => 'abcd\xe6\x88\x91\xe7\x9a\x84'
struct.unpack(fmt, s)
# output => ('abc', 'd\xe6\x88', 59281, 33946)
Basic encoders / decoders
The python distribution bundles more than 100 codecs(encoder/decoder) for text to byte conversion and vice-versa. Each codec has a name like ‘utf_8’, and often aliases, such as ‘utf8’, ‘utf-8’ and ‘U8’, which you can use as the encoding argument in functions like open(), str.encode(), bytes.decode() and so on.
Understanding encode/decode problems
Although there is a generic UnicodeError exception, almost always the error reported is more specific: either an UnicodeEncodeError, when converting str to binary sequnces or an UnicodeDecodeError when reading binary sequneces into str.
How to discover the encoding of a byte sequences
The encoding of a byte sequences can not be discovered, except you are told.
Some communication protocols and file formats, like HTTP and XML, contain headers that explicitly tell us how the content is encoded.
BOM: a useful gremlin
1 | u16 = u'我的' |
The buytes of u16 include b’\xff\xfe’, which is a BOM, byte-order mark, denoting the ‘little-endian’ byte ordering of the Intel CPU where the encoding was performed.
‘little-endian’ and ‘big-endian’
Handling text files
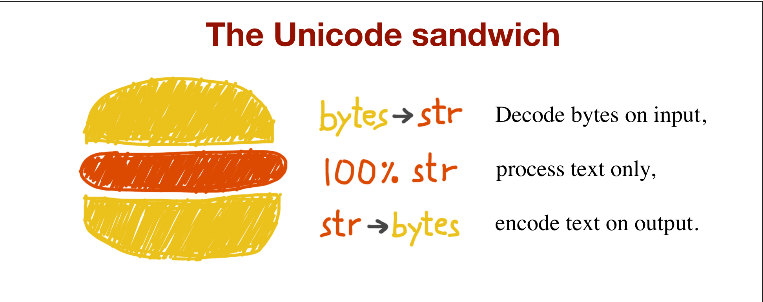
The best practice for handling text is the ‘Unicode sandwich’(e.g. above figure). This means that bytes should be decoded to str as early as possible on input, e.g. when opening a file for reading. The ‘meat’ of the sandwich is the business logic of your program, where text handling is done exclusively on str objects. You should never be encoding or decoding in the middle of other processing. On output, the str are encoded to bytes as late as possible, e.g. when writting text to file.
Normalizing Unicode for saner comparisons
String comparisons are complicated by the fact that Unicode has combining characters: diacritics and other marks that attach to the preceding character, appearing as one when printed.
1 | # python 3.5 |
The code point \u0301 is the COMBINING ACUTE ACCENT, in the Unicode standard, sequences like ‘é’ and ‘e\u0301’ are called ‘canonical equivalents’, and applications are supposed to treat them as the same. But python sees this two different sequences of code points, and considers them not equal. The solutions is to use Unicode normalization, provided by the unicodedata.normalize function.
The first argument to unicodeddata.normalize function is one of four strings: ‘NFC’, ‘NFD’, ‘NFKC’, ‘NFKD’.
-NFC: composes the code points to produce the shortest equivalent string.
-NFD: expanding composed characters into base characters and separate combining characters.
1 | # python 3.5 |
-NFKC & NFKD: stands for “compatibility”, they are stronger forms of normalization, affecting the so called “compatibility characters”